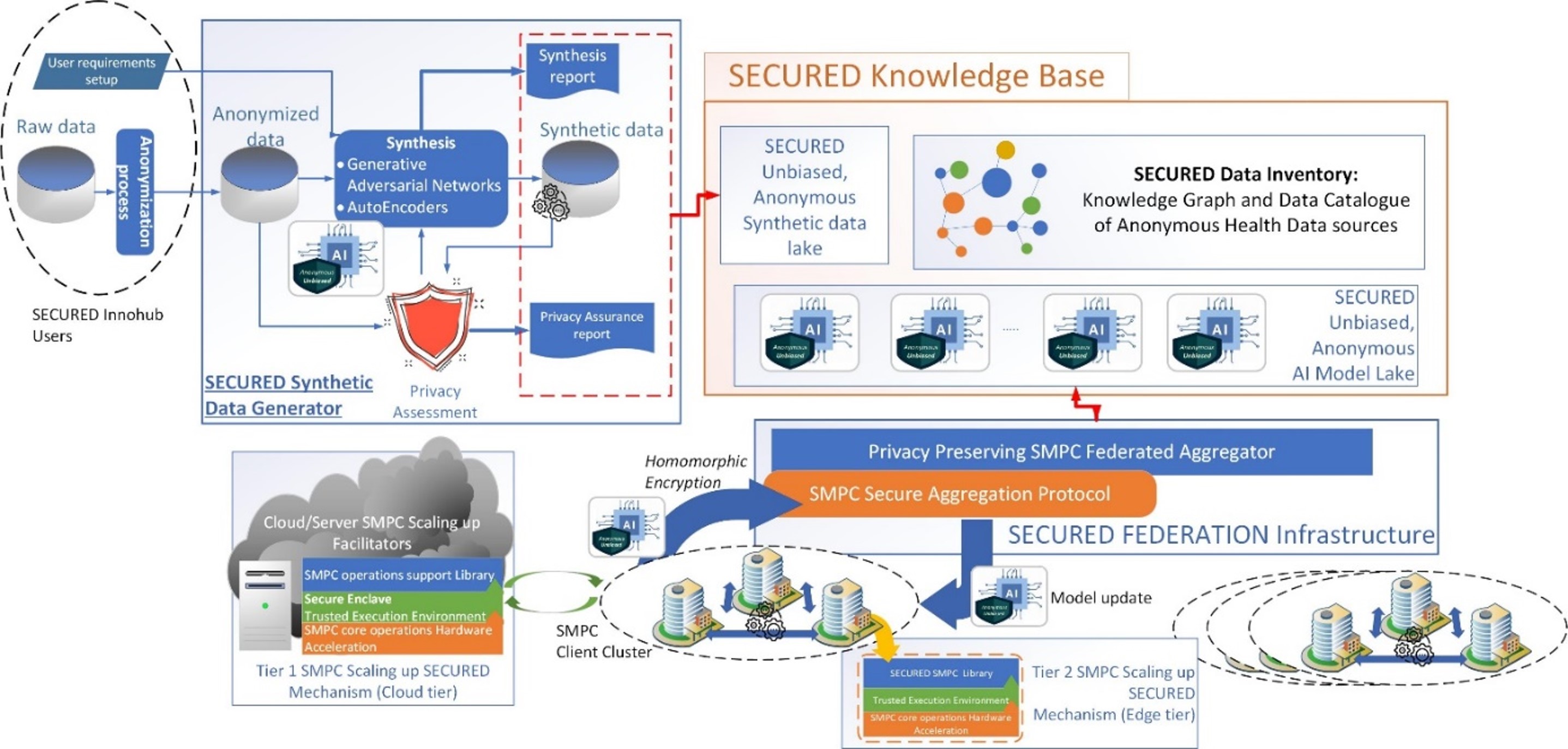
SECURED concept and Architecture
Concept
In SECURED, we offer a one stop collaboration hub (the SECURED Innohub) that can provide a secure and trusted environment for decentralized, cooperative processing of health data through SMPC techniques as well as generation of new, synthetic data and anonymization and anonymization assessment to health data providers and users. Our vision is to facilitate the broad adoption of health datasets across Europe by making the interconnection between EU health data hubs, the health data analytics research community, health application innovators (like Healthcare SMEs) as well as end users. The SECURED Innohub is offering apart from an SMPC and anonymization framework (with appropriate tools and services), the means to engage its members in the EU health data community by providing training and well as synthetic data to stem health data analysis research, medical education and an increase of the associated datasets volume and considerably reduce their bias. The SECURED vision is to kick start an EU cross-border health data collaboration ecosystem for data providers, data researchers and innovators that will be able to produce new AI based data analytics solutions and stem innovation.
The SECURED overall approach follows two parallel, independent yet interacting flows to innovation, the data flow and the processing flow, as seen in the figure.
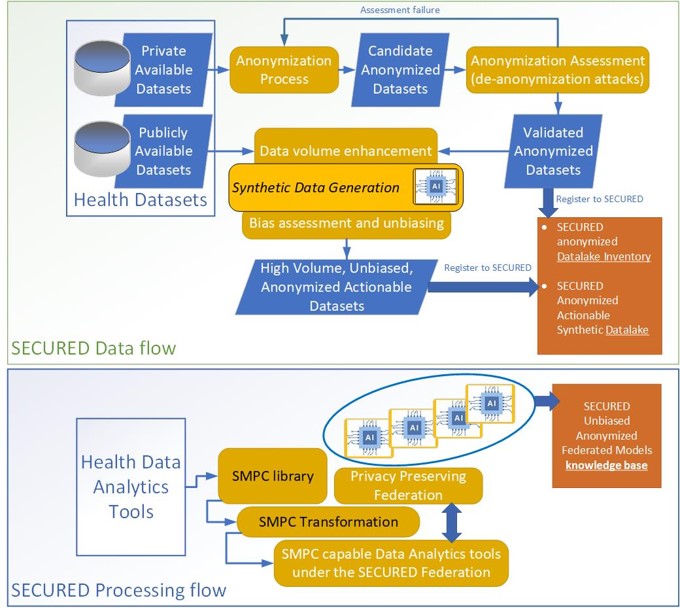
SECURED Data Flow
In the SECURED data flow the main goal is to help Health Data producers (e.g. EU health data hubs, hospitals, healthcare facilities) to properly anonymize their data by making sure that their anonymized data cannot get deanonymized and also to make sure through synthetic data generation mechanisms that they have sufficient volume for training AI models and performing data analysis (to extract useful results). In the SECURED data flow public or private datasets EU health hub datasets are considered. The SECURED solution offers the anonymization tools to anonymize such datasets but also offers an anonymity assessment mechanism that validates by performing de-anonymization attacks and generating anonymization scores. If such scores fail to reach a threshold (determined by the data producer) then the anonymization process is repeated with different parameters. Once acceptable anonymization is performed then the anonymized datasets are evaluated for their volume, if they are used for training AI deep learning models. Using synthetic data generation techniques offered by the SECURED solution, the EU data hubs (or data producers in general that participate in the SECURED Innohub) can enhance their datasets to sufficient volumes. A similar approach is followed for public datasets that don’t have enough volume. Apart from that, the SECURED solution’s tools make sure that the final anonymized datasets are not biased. If public, synthetic or anonymized data are found biased then an unbiasing process is offered by the SECURED solution to resolve this issue. Eventually, the end outcome of the SECURED data flow is unbiased, anonymized actionable datasets at the data producer premises (e.g in the EU data hub’s data lakes) that are however, registered appropriately in the SECURED Innohub Knowledge base and more specifically in the SECURED Innohub dataset inventory. This allows any member of the SECURED Innohub to be aware of the available anonymous datasets that all other members have at their disposal. Apart from that, when fully synthetic data have been generated for a given purpose, such actionable datasets are stored in a datalake within the knowledge base of the SECURED Innohub for usage by the Innohub’s members.
SECURED Processing Flow
Architecture